クラスタリングとは分類そのものを作成する手法
クラスタリングは複数の項目から対象のクラスターを分類する手法。小売りの現場での主な用途としては
- 顧客の購買履歴を使用した分類
- 店舗の立地条件などを使用した分類
- 商品の売れ行きなどを使用した分類
などがある。指標が売上金額など単純な場合は経験的に分類してもいいが、指標が多岐にわたる場合はなかなか適切な判断が難しい。
分類とクラスタリングが異なるのは、クラスタリングが「教師なし学習」である点。こちらが用意した分類に落とし込むのではなく、与えられたデータをもとに分類自体を行う点が大きく異なる。
k-means法はクラスタリングの中でも速度に優れる。ランダムに設定したクラスタの重心を設定し、各点と重心との距離が最短になるよう繰り返していく。
まずはざっくり
検索したら手軽に試せそうなコードがあったので活用させてもらう。使用するライブラリはscikit-learnになる。
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
# データセットを読み込み
cust_df = pd.read_csv("http://pythondatascience.plavox.info/wp-content/uploads/2016/05/Wholesale_customers_data.csv")
cust_df
------------
Channel Region Fresh Milk Grocery Frozen Detergents_Paper Delicassen
0 2 3 12669 9656 7561 214 2674 1338
1 2 3 7057 9810 9568 1762 3293 1776
2 2 3 6353 8808 7684 2405 3516 7844
3 1 3 13265 1196 4221 6404 507 1788
4 2 3 22615 5410 7198 3915 1777 5185
... ... ... ... ... ... ... ... ...
435 1 3 29703 12051 16027 13135 182 2204
436 1 3 39228 1431 764 4510 93 2346
437 2 3 14531 15488 30243 437 14841 1867
438 1 3 10290 1981 2232 1038 168 2125
439 1 3 2787 1698 2510 65 477 52
440 rows × 8 columns8列。欠損・重複なし。
ChannelとRegionは分類項目なので除去する。
del(cust_df['Channel'])
del(cust_df['Region'])
cust_df
--------------
Fresh Milk Grocery Frozen Detergents_Paper Delicassen
0 12669 9656 7561 214 2674 1338
1 7057 9810 9568 1762 3293 1776
2 6353 8808 7684 2405 3516 7844
3 13265 1196 4221 6404 507 1788
4 22615 5410 7198 3915 1777 5185
... ... ... ... ... ... ...
435 29703 12051 16027 13135 182 2204
436 39228 1431 764 4510 93 2346
437 14531 15488 30243 437 14841 1867
438 10290 1981 2232 1038 168 2125
439 2787 1698 2510 65 477 52
440 rows × 6 columnsdel関数めっちゃ便利や…。dropにaxis=1してた。
つづいて、各列をデータフレームから行列に変換して分析できる形にする。
cust_array = np.array([cust_df['Fresh'].tolist(),
cust_df['Milk'].tolist(),
cust_df['Grocery'].tolist(),
cust_df['Frozen'].tolist(),
cust_df['Milk'].tolist(),
cust_df['Detergents_Paper'].tolist(),
cust_df['Delicassen'].tolist()
], np.int32)
cust_array = cust_array.T # 転置
cust_array
-------------
array([[12669, 9656, 7561, ..., 9656, 2674, 1338],
[ 7057, 9810, 9568, ..., 9810, 3293, 1776],
[ 6353, 8808, 7684, ..., 8808, 3516, 7844],
...,
[14531, 15488, 30243, ..., 15488, 14841, 1867],
[10290, 1981, 2232, ..., 1981, 168, 2125],
[ 2787, 1698, 2510, ..., 1698, 477, 52]], dtype=int32)いざクラスタリング
pred = KMeans(n_clusters=4).fit_predict(cust_array)
pred
-----------
array([0, 0, 0, 0, 1, 0, 0, 0, 0, 3, 0, 0, 1, 1, 1, 0, 3, 0, 0, 0, 0, 0,
1, 2, 1, 0, 0, 0, 3, 1, 0, 0, 1, 1, 0, 0, 1, 3, 3, 1, 1, 0, 3, 3,
0, 3, 3, 2, 0, 3, 0, 0, 1, 3, 1, 0, 3, 3, 0, 0, 0, 2, 0, 3, 0, 3,
0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 3, 0, 0, 0, 3, 0, 1, 0, 2, 2, 1,
0, 1, 0, 0, 3, 0, 3, 0, 0, 0, 0, 0, 3, 3, 0, 1, 0, 0, 0, 3, 0, 3,
0, 3, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 3, 0, 0, 0, 1, 0, 0, 0, 0,
0, 3, 3, 0, 0, 3, 0, 0, 0, 3, 0, 3, 0, 0, 0, 0, 3, 3, 0, 3, 0, 3,
1, 0, 0, 0, 0, 2, 3, 2, 0, 0, 0, 0, 0, 3, 0, 0, 0, 3, 0, 0, 1, 0,
0, 0, 3, 3, 1, 0, 0, 3, 0, 0, 0, 3, 0, 3, 0, 0, 0, 3, 3, 0, 3, 0,
0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1,
0, 0, 0, 3, 0, 0, 0, 0, 0, 3, 0, 1, 3, 1, 0, 0, 1, 1, 0, 0, 1, 0,
3, 3, 3, 1, 3, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1,
0, 0, 0, 1, 0, 0, 0, 3, 1, 0, 0, 0, 0, 0, 0, 3, 0, 0, 3, 3, 3, 0,
0, 3, 0, 1, 3, 0, 0, 3, 0, 0, 0, 3, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0,
0, 3, 1, 3, 0, 1, 0, 0, 0, 0, 0, 0, 0, 3, 0, 0, 3, 1, 0, 3, 0, 3,
0, 3, 0, 0, 1, 3, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0,
0, 0, 3, 1, 0, 0, 1, 0, 1, 0, 3, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0,
3, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 3, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0,
3, 0, 0, 0, 1, 0, 0, 0, 3, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 3, 0, 0],
dtype=int32)クラスタリングした結果をもとのDFに記入
cust_df['cluster_id']=pred
cust_df
--------------
Fresh Milk Grocery Frozen Detergents_Paper Delicassen cluster_id
0 12669 9656 7561 214 2674 1338 0
1 7057 9810 9568 1762 3293 1776 0
2 6353 8808 7684 2405 3516 7844 0
3 13265 1196 4221 6404 507 1788 0
4 22615 5410 7198 3915 1777 5185 1
... ... ... ... ... ... ... ...
435 29703 12051 16027 13135 182 2204 1
436 39228 1431 764 4510 93 2346 1
437 14531 15488 30243 437 14841 1867 3
438 10290 1981 2232 1038 168 2125 0
439 2787 1698 2510 65 477 52 0
440 rows × 7 columnsおお…。各グループの数を確認。
cust_df['cluster_id'].value_counts()
---------------
0 279
3 78
1 76
2 7
Name: cluster_id, dtype: int64最初に設定したクラスタがランダムなので、参考にしたサイトとは微妙に数値が異なる。
積み上げグラフで可視化する。
import matplotlib.pyplot as plt
clusterinfo = pd.DataFrame()
for i in range(4):
clusterinfo['cluster' + str(i)] = cust_df[cust_df['cluster_id'] == i].mean()
clusterinfo = clusterinfo.drop('cluster_id')
my_plot = clusterinfo.T.plot(kind='bar', stacked=True, title="Mean Value of 4 Clusters")
my_plot.set_xticklabels(my_plot.xaxis.get_majorticklabels(), rotation=0)
[Text(0, 0, 'cluster0'),
Text(0, 0, 'cluster1'),
Text(0, 0, 'cluster2'),
Text(0, 0, 'cluster3')]
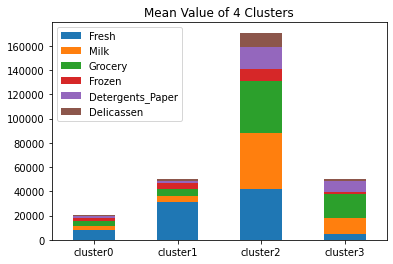
クラスタ0は消費自体が少ない。クラスタ1は生鮮食品多め。2はかなり消費高め。3は雑貨と飲料がメイン。
なんとなく7つのクラスターにしてみる。
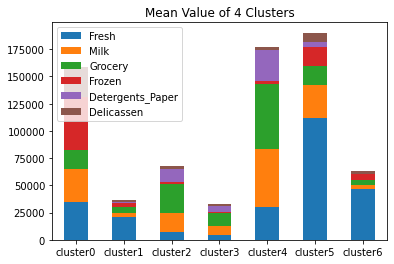
なんとなく分類はできたが、判断には実務知識要りそうな結果になった。あんまり細かくしすぎると逆に分かりにくくなることもありそう。
けっこうボリューム大きかったので、応用はまた次回。
参考文献
