AutoMLのPyCaretを使って、分類(教師なし)を試みる。今回も下記書籍を参考にする。

!pip install numba==0.53 # 依存関係エラー対応
# https://stackoverflow.com/questions/70148065/numba-needs-numpy-1-20-or-less-for-shapley-import
!pip install pandas-profiling==3.1.0 # エラー対応 実行後にランタイム再起動
!pip install pycaret
from pycaret.utils import enable_colab
enable_colab()今回も2022年8月現在引っかかるエラー対応をして、Colabにライブラリを読み込む。
データ読み込み
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df_iris = pd.DataFrame(iris.data, columns = iris.feature_names)アヤメを読み込んで、データフレームに落とし込む。
前処理
from pycaret.clustering import *
data_clust = setup(data = df_iris,
normalize = False,
session_id = 0,
silent = True)今回はクラスタリングを試すので、クラスタリングをインポートする。
前処理も簡単。正規化なしで、ざっくり終わらせる。
models()
-----
Name Reference
ID
kmeans K-Means Clustering sklearn.cluster._kmeans.KMeans
ap Affinity Propagation sklearn.cluster._affinity_propagation.Affinity...
meanshift Mean Shift Clustering sklearn.cluster._mean_shift.MeanShift
sc Spectral Clustering sklearn.cluster._spectral.SpectralClustering
hclust Agglomerative Clustering sklearn.cluster._agglomerative.AgglomerativeCl...
dbscan Density-Based Spatial Clustering sklearn.cluster._dbscan.DBSCAN
optics OPTICS Clustering sklearn.cluster._optics.OPTICS
birch Birch Clustering sklearn.cluster._birch.Birch
kmodes K-Modes Clustering kmodes.kmodes.KModes利用可能なモデル一覧。kmeansとmeanshift以外分からないな…。
今回は定番のk-meansとする。
モデル作成
kmeans = create_model('kmeans', num_clusters = 7)
print(kmeans)なんとなくクラスター数は7にしてみる。
可視化
plot_model(kmeans)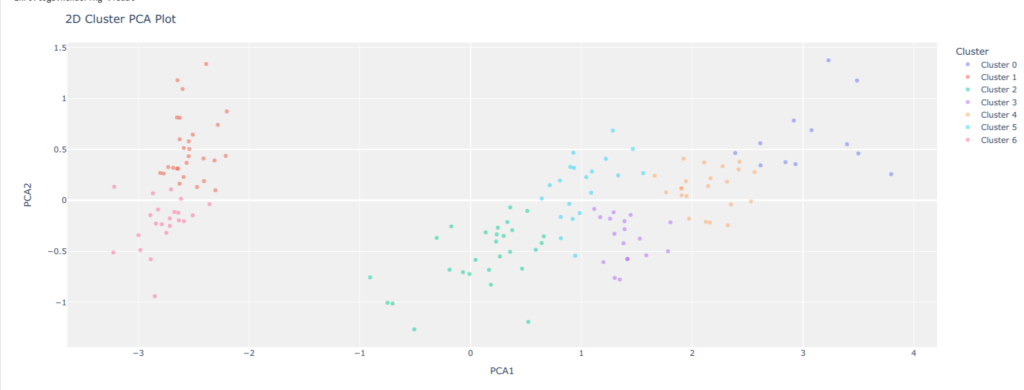
クラスターごとに色分けした2次元プロット。右側が若干ごちゃついているが、きれいに分けられているように見える。
PCAは主成分分析。多次元データを圧縮して、より区別が付きやすいデータに見せ方を変えてくれる。これ自体も教師なし学習。
ただ、元データの行列散布図も確認した上で使用する。
# エルボー図
plot_model(kmeans, plot = 'elbow')k-meansでクラスタ数を指定する際に悩むのが、適切なクラスタ数を指定しているかどうか。
エルボー図はSSEの数値がクラスタ数でどう変化するのかをグラフ化して表す。SSEが小さいほど適切にクラスタリングできているはずなので、SSEがガクッと下がったところが適切なクラスタ数とみなすことができる。
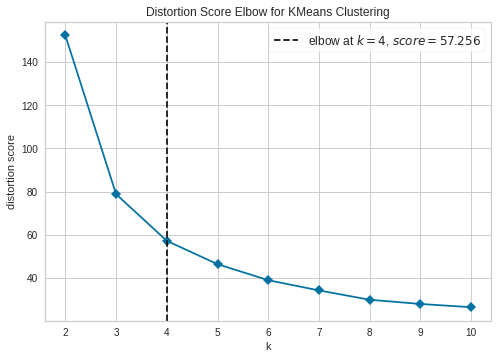
この場合、4までガクッと落ちているので、おそらく4あたりが適切ではないかと考える。
# シルエット図を出力
plot_model(kmeans, plot = 'silhouette')ちょっと理屈が分からないので、おいおい勉強する。
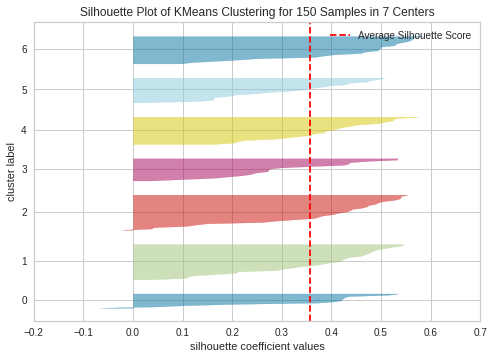
予測
最後は予測して、クラスタ番号を各データに振っていく。
ret = predict_model(kmeans, data = df_iris)
ret
-----
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) Cluster
0 5.1 3.5 1.4 0.2 Cluster 1
1 4.9 3.0 1.4 0.2 Cluster 6
2 4.7 3.2 1.3 0.2 Cluster 6
3 4.6 3.1 1.5 0.2 Cluster 6
4 5.0 3.6 1.4 0.2 Cluster 1
... ... ... ... ... ...
145 6.7 3.0 5.2 2.3 Cluster 4
146 6.3 2.5 5.0 1.9 Cluster 3
147 6.5 3.0 5.2 2.0 Cluster 4
148 6.2 3.4 5.4 2.3 Cluster 4
149 5.9 3.0 5.1 1.8 Cluster 3